

体系课-大数据工程师2022||重磅首发|课件源码电子书数据完整|完结无秘
┣━体系课-大数据工程师2022
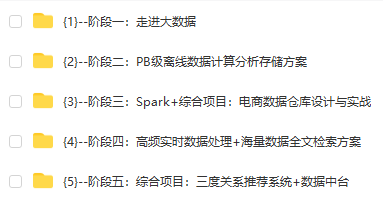
┣━{1}–阶段一:走进大数据
┣━{1}–学好大数据先攻克Linux
┣━{1}–第1章笑傲大数据成长体系课【必看】
┣━[1.1.1.1]–1-2笑傲大数据:总体介绍.mp4
┣━{2}–第2章Linux虚拟机安装配置
┣━[1.1.2.4]–2-4使用SecureCRT连接Linux虚拟机之方式一.mp4
┣━[1.1.2.5]–2-5使用SecureCRT连接Linux虚拟机之方式二.mp4
┣━[1.1.2.3]–2-3使用克隆的方式创建Linux虚拟机.mp4
┣━[1.1.2.1]–2-1如何安装Linux虚拟机.mp4
┣━[1.1.2.2]–2-2使用Vmware安装Linux虚拟机.mp4
┣━[1.1.2.6]–2-6SecureCRT配置修改.mp4
┣━{3}–第3章Linux极速上手
┣━[1.1.3.10]–3-11Linux常见高级命令之三剑客(sed).mp4
┣━[1.1.3.11]–3-12Linux常见高级命令之三剑客(awk).mp4
┣━[1.1.3.2]–3-2Linux常见高级命令之wc的使用.mp4
┣━[1.1.3.6]–3-6Linux常见高级命令之date的使用.mp4
┣━[1.1.3.7]–3-7Linux常见高级命令之ps和netstat的使用.mp4
┣━[1.1.3.8]–3-8Linux常见高级命令之jps+top+kill的使用.mp4
┣━[1.1.3.1]–3-1Linux常见高级命令之vi的使用.mp4
┣━[1.1.3.4]–3-4Linux常见高级命令之uniq的使用.mp4
┣━[1.1.3.3]–3-3Linux常见高级命令之sort的使用.mp4
┣━[1.1.3.5]–3-5Linux常见高级命令之head的使用.mp4
┣━[1.1.3.9]–3-9Linux常见高级命令之三剑客(grep).mp4
┣━{4}–第4章Linux试炼之配置与shell实战
┣━[1.1.4.10]–4-10shell扩展.mp4
┣━[1.1.4.4]–4-4开发执行第一个shell脚本.mp4
┣━[1.1.4.6]–4-6shell中四种变量的使用.mp4
┣━[1.1.4.11]–4-11Linux中的定时器crontab.mp4
┣━[1.1.4.2]–4-2Linux高级配置之hostname设置.mp4
┣━[1.1.4.8]–4-8shell中的循环和判断之while循环.mp4
┣━[1.1.4.5]–4-5shell中变量的定义.mp4
┣━[1.1.4.7]–4-7shell中的循环和判断之for循环.mp4
┣━[1.1.4.1]–4-1Linux高级配置之静态ip设置.mp4
┣━[1.1.4.9]–4-9shell中的循环和判断之if判断.mp4
┣━{5}–第5章Linux总结与走进大数据
┣━[1.1.5.2]–5-2Linux总结.mp4
┣━[1.1.5.5]–5-5大数据的4V特征.mp4
┣━[1.1.5.1]–5-1实战:在Linux上安装配置JDK.mp4
┣━[1.1.5.3]–5-3什么是大数据.mp4
┣━[1.1.5.4]–5-4大数据产生的背景.mp4
┣━[1.1.5.6]–5-6大数据的行业应用.mp4
┣━{2}–大数据起源之初识Hadoop
┣━{1}–第1章初识Hadoop
┣━[1.2.1.2]–1-2Hadoop发行版及核心组件介绍.mp4
┣━[1.2.1.1]–1-1什么是Hadoop.mp4
┣━{2}–第2章Hadoop的两种安装方式
┣━[1.2.2.3]–2-3Hadoop分布式集群安装部署.mp4
┣━[1.2.2.4]–2-4Hadoop分布式集群安装部署.mp4
┣━[1.2.2.1]–2-1Hadoop伪分布集群安装部署.mp4
┣━[1.2.2.2]–2-2Hadoop伪分布集群安装部署.mp4
┣━[1.2.2.5]–2-5Hadoop的客户端节点.mp4
┣━{3}–Hadoop之HDFS的使用
┣━{1}–第1章HDFS介绍
┣━[1.3.1.1]–1-1HDFS介绍.mp4
┣━[1.3.1.2]–1-2HDFS的Shell介绍.mp4
┣━{2}–第2章HDFS基础操作
┣━[1.3.2.1]–2-1HDFS的常见Shell操作.mp4
┣━[1.3.2.2]–2-2HDFS案例实操.mp4
┣━{3}–第3章Java操作HDFS
┣━[1.3.3.1]–3-1Java代码操作HDFS.mp4
┣━[1.3.3.2]–3-2Java代码操作HDFS.mp4
┣━{4}–Hadoop之HDFS核心进程剖析
┣━{1}–第1章初识NameNode
┣━[1.4.1.1]–1-1NameNode介绍.mp4
┣━[1.4.1.2]–1-2NameNode深入.mp4
┣━{2}–第2章NameNode进阶
┣━[1.4.2.3]–2-3NameNode总结.mp4
┣━[1.4.2.2]–2-2DataNode介绍.mp4
┣━[1.4.2.1]–2-1SecondaryNameNode介绍.mp4
┣━{3}–第3章HDFS高级
┣━[1.4.3.3]–3-3实战:定时上传数据至HDFS.mp4
┣━[1.4.3.5]–3-5本周总结+寄语.mp4
┣━[1.4.3.1]–3-1HDFS的回收站.mp4
┣━[1.4.3.4]–3-4HDFS的高可用和高扩展.mp4
┣━[1.4.3.2]–3-2HDFS的安全模式.mp4
┣━{4}–第4章【扩展内容】HDFS写数据源码剖析
┣━[1.4.4.5]–4-5create方法源码调用过程分析(下).mp4
┣━[1.4.4.3]–4-3源码概览及源码基础环境配置.mp4
┣━[1.4.4.4]–4-4create方法源码调用过程分析(上).mp4
┣━[1.4.4.7]–4-7write方法源码调用过程分析(下).mp4
┣━[1.4.4.1]–4-1RPC原理分析及案例应用.mp4
┣━[1.4.4.6]–4-6write方法源码调用过程分析(上).mp4
┣━{5}–Hadoop之初识MR
┣━{1}–第1章初识MapReduce
┣━[1.5.1.1]–1-1MapReduce介绍.mp4
┣━[1.5.1.2]–1-2MapReduce执行原理.mp4
┣━{2}–第2章实战:WordCount
┣━[1.5.2.2]–2-2实战:WordCount案例开发.mp4
┣━[1.5.2.3]–2-3实战:WordCount案例开发.mp4
┣━[1.5.2.1]–2-1WordCount案例图解.mp4
┣━{3}–第3章深入MapReduce
┣━[1.5.3.1]–3-1MapReduce任务日志查看.mp4
┣━[1.5.3.3]–3-3MapReduce程序扩展.mp4
┣━[1.5.3.2]–3-2停止Hadoop集群中的任务.mp4
┣━{4}–第4章精讲Shuffle执行过程及源码分析输入输出
┣━[1.5.4.2]–4-2Hadoop中的序列化机制.mp4
┣━[1.5.4.1]–4-1Shuffle执行过程分析.mp4
┣━[1.5.4.3]–4-3InputFormat层级分析.mp4
┣━[1.5.4.4]–4-4InputFormat之getSplits源码剖析.mp4
┣━[1.5.4.6]–4-6InputFormat之RecordReader源码剖析.mp4
┣━[1.5.4.7]–4-7OutputFormat源码剖析.mp4
┣━{2}–阶段二:PB级离线数据计算分析存储方案
┣━{1}–拿来就用的企业级解决方案
┣━{1}–第1章剖析小文件问题与企业级解决方案
┣━[2.1.1.2]–1-2小文件问题之SequenceFile.mp4
┣━[2.1.1.1]–1-1小文件问题之SequenceFile.mp4
┣━[2.1.1.4]–1-4案例:小文件存储和计算.mp4
┣━[2.1.1.3]–1-3小文件问题之MapFile.mp4
┣━{2}–第2章剖析数据倾斜问题与企业级解决方案
┣━[2.1.2.2]–2-2数据倾斜案例实战.mp4
┣━[2.1.2.3]–2-3数据倾斜案例实战.mp4
┣━[2.1.2.1]–2-1数据倾斜问题分析.mp4
┣━{3}–第3章YARN实战
┣━[2.1.3.3]–3-3案例:YARN多资源队列配置和使用.mp4
┣━[2.1.3.2]–3-2YARN中的调度器分析.mp4
┣━[2.1.3.1]–3-1YARN的基本情况介绍.mp4
┣━{4}–第4章Hadoop官方文档使用指北【授人以鱼不如授人以渔】
┣━[2.1.4.1]–4-1Hadoop官方文档使用指南.mp4
┣━[2.1.4.3]–4-3Hadoop在HDP中的使用.mp4
┣━[2.1.4.2]–4-2Hadoop在CDH中的使用.mp4
┣━{5}–第5章Hadoop核心复盘
┣━[2.1.5.1]–5-1本周总结+寄语.mp4
┣━{6}–第6章【福利加油站】
┣━[2.1.6.2]–6-2【加餐】大厂资深HR教你如何准备简历和面试.mp4
┣━[2.1.6.1]–6-1【加餐】大数据技术揭开抖音推荐的真相.mp4
┣━{2}–Flume从0到高手一站式养成记
┣━{1}–第1章极速入门Flume
┣━[2.2.1.3]–1-3Flume安装部署.mp4
┣━[2.2.1.1]–1-1快速了解Flume.mp4
┣━[2.2.1.2]–1-2Flume的三大核心组件.mp4
┣━{2}–第2章极速上手Flume使用
┣━[2.2.2.1]–2-1Flume的HelloWorld.mp4
┣━[2.2.2.2]–2-2案例:采集文件内容上传至HDFS.mp4
┣━[2.2.2.3]–2-3案例:采集网站日志上传至HDFS.mp4
┣━{3}–第3章精讲Flume高级组件
┣━[2.2.3.1]–3-1Flume高级组件之SourceInterceptors.mp4
┣━[2.2.3.2]–3-2Flume高级组件之ChannelSelectors.mp4
┣━[2.2.3.3]–3-3Flume高级组件之SinkProcessors.mp4
┣━{4}–第4章Flume出神入化篇
┣━[2.2.4.2]–4-2Flume优化.mp4
┣━[2.2.4.3]–4-3Flume进程监控.mp4
┣━[2.2.4.1]–4-1各种自定义组件.mp4
┣━{5}–第5章Flume核心复盘
┣━[2.2.5.1]–5-1本周总结+寄语.mp4
┣━{3}–数据仓库Hive从入门到小牛
┣━{1}–第1章快速了解Hive
┣━[2.3.1.1]–1-1快速了解Hive.mp4
┣━{2}–第2章数据库与数据仓库区别
┣━[2.3.2.1]–2-1数据库和数据仓库的区别.mp4
┣━[2.3.2.2]–2-2Hive安装部署.mp4
┣━{3}–第3章Hive基础使用
┣━[2.3.3.2]–3-2Hive使用方式之JDBC方式.mp4
┣━[2.3.3.3]–3-3Set命令的使用.mp4
┣━[2.3.3.1]–3-1Hive使用方式之命令行方式.mp4
┣━[2.3.3.4]–3-4Hive的日志配置.mp4
┣━{4}–第4章Hive核心实战
┣━[2.3.4.10]–4-10Hive数据处理综合案例(下).mp4
┣━[2.3.4.2]–4-2Hive中表的操作.mp4
┣━[2.3.4.8]–4-8Hive表类型之桶表+视图.mp4
┣━[2.3.4.9]–4-9Hive数据处理综合案例(上).mp4
┣━[2.3.4.1]–4-1Hive中数据库的操作.mp4
┣━[2.3.4.4]–4-4Hive中数据类型的应用.mp4
┣━[2.3.4.5]–4-5Hive表类型之内部表+外部表.mp4
┣━[2.3.4.6]–4-6Hive表类型之内部分区表.mp4
┣━[2.3.4.3]–4-3Hive中数据类型的应用.mp4
┣━[2.3.4.7]–4-7Hive表类型之外部分区表.mp4
┣━{5}–第5章Hive高级函数实战
┣━[2.3.5.2]–5-2Hive高级函数之行转列.mp4
┣━[2.3.5.5]–5-5Hive的分组和去重函数.mp4
┣━[2.3.5.1]–5-1Hive高级函数之分组排序取TopN.mp4
┣━[2.3.5.3]–5-3Hive高级函数之列转行.mp4
┣━[2.3.5.4]–5-4Hive的排序函数.mp4
┣━{6}–第6章Hive技巧与核心复盘
┣━[2.3.6.2]–6-2Hive的Web工具-HUE.mp4
┣━[2.3.6.3]–6-3本周总结+寄语.mp4
┣━{4}–Hive扩展内容
┣━{1}–第1章常见数据压缩格式的使用
┣━[2.4.1.5]–1-5Gzip+Bzip2压缩格式演示.mp4
┣━[2.4.1.1]–1-1常见的数据压缩格式介绍.mp4
┣━[2.4.1.2]–1-2数据压缩格式选择建议和压缩位置.mp4
┣━[2.4.1.3]–1-3数据压缩格式案例实战分析.mp4
┣━[2.4.1.6]–1-6Lz4+Snappy压缩格式演示.mp4
┣━[2.4.1.7]–1-7Lzo压缩格式演示.mp4
┣━[2.4.1.4]–1-4未压缩+Deflate压缩格式演示.mp4
┣━{2}–第2章常见数据存储格式的使用
┣━[2.4.2.2]–2-2数据存储格式之SequenceFile的原理及使用.mp4
┣━[2.4.2.3]–2-3数据存储格式之RCFile的原理及使用.mp4
┣━[2.4.2.5]–2-5数据存储格式之Parquet的原理及使用.mp4
┣━[2.4.2.1]–2-1数据存储格式之TextFile的原理及使用.mp4
┣━[2.4.2.4]–2-4数据存储格式之ORC的原理及使用.mp4
┣━[2.4.2.6]–2-6数据存储格式总结.mp4
┣━{5}–快速上手NoSQL数据库HBase
┣━{1}–第1章快速了解HBase
┣━[2.5.1.1]–1-7HBase逻辑存储模型.mp4
┣━{2}–第2章快速上手使用HBase
┣━[2.5.2.1]–2-1HBase集群安装部署.mp4
┣━[2.5.2.3]–2-3HBase常用命令之增删改查命令和命名空间的操作.mp4
┣━[2.5.2.4]–2-4HBaseJavaAPI开发环境配置.mp4
┣━[2.5.2.5]–2-5HBaseJavaAPI之增加和查询操作.mp4
┣━[2.5.2.7]–2-7HBaseJavaAPI之创建表和删除表.mp4
┣━[2.5.2.2]–2-2HBase常用命令之基础命令和DDL命令.mp4
┣━[2.5.2.6]–2-6HBaseJavaAPI之查询多版本数据和删除操作.mp4
┣━{3}–第3章深入HBase架构原理
┣━[2.5.3.1]–3-1Region概念详解.mp4
┣━[2.5.3.2]–3-3HBase架构详解.mp4
┣━[2.5.3.7]–3-8Region的负载均衡策略.mp4
┣━[2.5.3.4]–3-5HFile文件及布隆过滤器介绍.mp4
┣━[2.5.3.6]–3-7Region的分裂机制.mp4
┣━[2.5.3.3]–3-4WAL预写日志系统.mp4
┣━[2.5.3.5]–3-6HFile的合并机制.mp4
┣━{4}–第4章HBase高级用法
┣━[2.5.4.2]–4-3Scan+Filter案例实战.mp4
┣━[2.5.4.1]–4-2Scan全表扫描功能介绍.mp4
┣━[2.5.4.4]–4-5HBase批量导入之BulkLoad.mp4
┣━[2.5.4.3]–4-4HBase批量导入之MapReduce.mp4
┣━{5}–第5章HBase调优策略和扩展内容
┣━[2.5.5.1]–5-1预分区、RowKey、列族的设计原则.mp4
┣━{3}–阶段三:Spark+综合项目:电商数据仓库设计与实战
┣━{1}–7天极速掌握Scala语言
┣━{1}–第1章Scala极速入门
┣━[3.1.1.1]–1-1快速了解Scala.mp4
┣━[3.1.1.2]–1-2Scala环境安装配置.mp4
┣━{2}–第2章Scala基础语法
┣━[3.1.2.3]–2-3Scala集合体系之Set.mp4
┣━[3.1.2.4]–2-4Scala集合体系之List.mp4
┣━[3.1.2.5]–2-5Scala集合体系之Map.mp4
┣━[3.1.2.6]–2-6Scala中的Array和Tuple.mp4
┣━[3.1.2.8]–2-8Scala中函数的使用.mp4
┣━[3.1.2.1]–2-1Scala中的变量和数据类型.mp4
┣━[3.1.2.2]–2-2Scala中的表达式和循环.mp4
┣━[3.1.2.7]–2-7Scala集合总结.mp4
┣━{3}–第3章Scala面向对象
┣━[3.1.3.4]–3-4Scala面向对象之main方法的使用.mp4
┣━[3.1.3.5]–3-5Scala面向对象之接口的使用.mp4
┣━[3.1.3.1]–3-1Scala面向对象之类的使用.mp4
┣━[3.1.3.3]–3-3Scala面向对象之apply方法.mp4
┣━{4}–第4章Scala函数式编程
┣━[3.1.4.1]–4-1Scala函数式编程介绍.mp4
┣━[3.1.4.2]–4-2Scala函数式编程之匿名函数和高阶函数.mp4
┣━[3.1.4.3]–4-3Scala函数式编程之常用高阶函数的使用.mp4
┣━{5}–第5章Scala高级特性
┣━[3.1.5.1]–5-1Scala高级特性之模式匹配.mp4
┣━[3.1.5.2]–5-2Scala高级特性之隐式转换.mp4
┣━{6}–第6章Scala核心复盘
┣━[3.1.6.1]–6-1本周总结+寄语.mp4
┣━{2}–Spark快速上手
┣━{1}–第1章初识Spark
┣━[3.2.1.1]–1-1快速了解Spark.mp4
┣━[3.2.1.2]–1-2SparkStandalone集群安装部署.mp4
┣━[3.2.1.3]–1-3SparkONYARN集群安装部署.mp4
┣━{2}–第2章解读Spark工作与架构原理
┣━[3.2.2.1]–2-1Spark工作原理分析.mp4
┣━[3.2.2.2]–2-2什么是RDD.mp4
┣━[3.2.2.3]–2-3Spark架构原理.mp4
┣━{3}–第3章Spark实战:单词统计
┣━[3.2.3.2]–3-2WordCount之Scala代码.mp4
┣━[3.2.3.3]–3-3WordCount之Java代码.mp4
┣━[3.2.3.4]–3-4Spark任务的三种提交方式.mp4
┣━[3.2.3.5]–3-5Spark开启historyServer服务.mp4
┣━[3.2.3.1]–3-1Spark项目开发环境配置.mp4
┣━{4}–第4章Transformation与Action开发实战
┣━[3.2.4.3]–4-3Transformation操作开发实战之Scala代码(.mp4
┣━[3.2.4.1]–4-1创建RDD的三种方式.mp4
┣━[3.2.4.5]–4-5Transformation操作开发实战之Java代码(上.mp4
┣━[3.2.4.6]–4-6Transformation操作开发实战之Java代码(下.mp4
┣━[3.2.4.7]–4-7Action操作开发实战之Scala代码.mp4
┣━[3.2.4.4]–4-4Transformation操作开发实战之Scala代码(.mp4
┣━[3.2.4.8]–4-8Action操作开发实战之Java代码.mp4
┣━[3.2.4.2]–4-2Transformation和Action介绍.mp4
┣━{5}–第5章RDD持久化
┣━[3.2.5.3]–5-3RDD持久化开发实战之Java代码.mp4
┣━[3.2.5.5]–5-5共享变量之Accumulator的使用.mp4
┣━[3.2.5.2]–5-2RDD持久化开发实战之Scala代码.mp4
┣━[3.2.5.4]–5-4共享变量之BroadcastVariable的使用.mp4
┣━{6}–第6章TopN主播统计
┣━[3.2.6.2]–6-2TopN主播统计代码实现之Scala代码.mp4
┣━[3.2.6.3]–6-3TopN主播统计代码实现之Java代码.mp4
┣━{7}–第7章面试与核心复盘
┣━[3.2.7.2]–7-2本周总结+寄语.mp4
┣━[3.2.7.1]–7-1面试题.mp4
┣━{3}–Spark性能优化的道与术
┣━{1}–第1章Spark三种任务提交模式
┣━[3.3.1.3]–1-3Spark任务的三种提交模式.mp4
┣━[3.3.1.1]–1-1宽依赖和窄依赖.mp4
┣━[3.3.1.2]–1-2Stage.mp4
┣━{2}–第2章Shuffle机制分析
┣━[3.3.2.2]–2-2三种Shuffle机制分析.mp4
┣━[3.3.2.1]–2-1Shuffle介绍.mp4
┣━{3}–第3章Spark之checkpoint
┣━[3.3.3.5]–3-5checkpoint源码分析之写操作.mp4
┣━[3.3.3.6]–3-6checkpoint源码分析之读操作.mp4
┣━[3.3.3.2]–3-2checkpoint和持久化的区别.mp4
┣━[3.3.3.4]–3-4checkpoint代码执行分析.mp4
┣━[3.3.3.1]–3-1checkpoint概述.mp4
┣━[3.3.3.3]–3-3checkpoint代码开发(Scala+Java).mp4
┣━{4}–第4章Spark程序性能优化企业级最佳实践
┣━[3.3.4.5]–4-6数据本地化.mp4
┣━[3.3.4.1]–4-1Spark程序性能优化分析.mp4
┣━[3.3.4.3]–4-3持久化或者checkpoint.mp4
┣━[3.3.4.2]–4-2高性能序列化类库Kryo的使用.mp4
┣━[3.3.4.4]–4-4JVM垃圾回收调忧.mp4
┣━{5}–第5章Spark性能优化之算子优化
┣━[3.3.5.2]–5-2算子优化之foreachPartition.mp4
┣━[3.3.5.3]–5-3算子优化之repartition的使用.mp4
┣━[3.3.5.1]–5-1算子优化之mapPartitions.mp4
┣━[3.3.5.4]–5-4算子优化之reduceByKey和groupByKey.mp4
┣━{6}–第6章极速上手SparkSql
┣━[3.3.6.6]–6-6load和save操作.mp4
┣━[3.3.6.2]–6-2DataFrame常见算子操作.mp4
┣━[3.3.6.3]–6-3DataFrame的sql操作.mp4
┣━[3.3.6.7]–6-7SaveMode的使用.mp4
┣━[3.3.6.1]–6-1SparkSql快速上手使用.mp4
┣━[3.3.6.4]–6-4RDD转换为DataFrame之反射方式.mp4
┣━[3.3.6.5]–6-5RDD转换为DataFrame之编程方式.mp4
┣━[3.3.6.8]–6-8内置函数介绍.mp4
┣━{7}–第7章Spark实战与核心复盘
┣━[3.3.7.1]–7-1实战:TopN主播统计-1.mp4
┣━[3.3.7.3]–7-3本周总结+寄语.mp4
┣━[3.3.7.2]–7-2实战:TopN主播统计-2.mp4
┣━{4}–Spark3.x扩展内容
┣━{1}–第1章快速上手使用Spark3.x
┣━[3.4.1.2]–1-2基于Spark3.x版本开发代码.mp4
┣━[3.4.1.3]–1-3在大数据集群中集成Spark3.x环境.mp4
┣━[3.4.1.1]–1-1Spark3.x版本介绍.mp4
┣━[3.4.1.5]–1-5向YARN集群中提交Spark2.x代码.mp4
┣━{2}–第2章Spark3.x版本中新特性的原理及应用
┣━[3.4.2.12]–2-12动态分区裁剪DPP(应用)-2.mp4
┣━[3.4.2.13]–2-13Spark3.x其他新特性分析.mp4
┣━[3.4.2.7]–2-7AQE之动态调整Join策略(应用).mp4
┣━[3.4.2.1]–2-1Spark1.x~3.x的演变历史.mp4
┣━[3.4.2.4]–2-4AQE之自适应调整Shuffle分区数量(应用)-1.mp4
┣━[3.4.2.8]–2-8AQE之动态优化倾斜的Join(原理).mp4
┣━[3.4.2.9]–2-9AQE之动态优化倾斜的Join(应用).mp4
┣━[3.4.2.3]–2-3AQE之自适应调整Shuffle分区数量(原理).mp4
┣━[3.4.2.5]–2-5AQE之自适应调整Shuffle分区数量(应用)-2.mp4
┣━[3.4.2.6]–2-6AQE之动态调整Join策略(原理).mp4
┣━[3.4.2.10]–2-10动态分区裁剪DPP(原理).mp4
┣━[3.4.2.11]–2-11动态分区裁剪DPP(应用)-1.mp4
┣━[3.4.2.2]–2-2Spark3.x新特性概述.mp4
┣━{3}–第3章SparkSQL集成Hive
┣━[3.4.3.2]–3-2在SparkSQL代码中集成Hive.mp4
┣━[3.4.3.6]–3-6使用SparkSQL向Hive表中写入数据.mp4
┣━[3.4.3.1]–3-1在SparkSQL命令行中集成Hive.mp4
┣━[3.4.3.3]–3-3使用insertInto向Hive表中写入数据.mp4
┣━[3.4.3.4]–3-4使用saveAsTable向Hive表中写入数据-1.mp4
┣━[3.4.3.5]–3-5使用saveAsTable向Hive表中写入数据-2.mp4
┣━[3.4.3.7]–3-7向集群中提交代码.mp4
┣━{5}–综合项目:电商数据仓库之用户行为数仓
┣━{1}–第1章电商数据仓库效果展示
┣━[3.5.1.1]–1-1项目效果展示.mp4
┣━[3.5.1.2]–1-2项目的由来.mp4
┣━{2}–第2章数据仓库前置技术
┣━[3.5.2.4]–2-4典型数仓系统架构分析.mp4
┣━[3.5.2.3]–2-3数据仓库分层.mp4
┣━[3.5.2.1]–2-1什么是数据仓库.mp4
┣━[3.5.2.2]–2-2数据仓库基础知识.mp4
┣━{3}–第3章电商数仓技术选型
┣━[3.5.3.3]–3-3服务器资源规划.mp4
┣━[3.5.3.2]–3-2整体架构设计.mp4
┣━[3.5.3.1]–3-1技术选型.mp4
┣━{4}–第4章数据生成与采集
┣━[3.5.4.3]–4-3采集用户行为数据【客户端数据】.mp4
┣━[3.5.4.7]–4-7采集商品订单相关数据【服务端数据】.mp4
┣━[3.5.4.4]–4-4Sqoop安装部署.mp4
┣━[3.5.4.6]–4-6Sqoop之数据导出功能.mp4
┣━[3.5.4.1]–4-1生成用户行为数据【客户端数据】.mp4
┣━[3.5.4.2]–4-2生成商品订单相关数据【服务端数据】.mp4
┣━[3.5.4.5]–4-5Sqoop之数据导入功能.mp4
┣━[3.5.4.8]–4-8采集商品订单相关数据【服务端数据】.mp4
┣━{5}–第5章用户行为数仓设计与实现
┣━[3.5.5.11]–5-11需求二之app层开发.mp4
┣━[3.5.5.14]–5-14需求三之dws层和app层开发.mp4
┣━[3.5.5.2]–5-2用户行为数据数仓开发之ods层脚本抽取.mp4
┣━[3.5.5.6]–5-6需求一之需求分析.mp4
┣━[3.5.5.8]–5-8需求一之app层开发.mp4
┣━[3.5.5.10]–5-10需求二之需求分析.mp4
┣━[3.5.5.19]–5-19需求五之需求分析.mp4
┣━[3.5.5.1]–5-1用户行为数据数仓开发之ods层开发.mp4
┣━[3.5.5.21]–5-21需求五之app层开发.mp4
┣━[3.5.5.23]–5-23需求六之需求分析.mp4
┣━[3.5.5.26]–5-26用户行为数据数仓表和任务脚本总结.mp4
┣━[3.5.5.4]–5-4用户行为数据数仓开发之dwd层脚本抽取.mp4
┣━[3.5.5.7]–5-7需求一之dws层开发.mp4
┣━[3.5.5.12]–5-12需求二之开发脚本.mp4
┣━[3.5.5.13]–5-13需求三之需求分析.mp4
┣━[3.5.5.15]–5-15需求三之开发脚本.mp4
┣━[3.5.5.20]–5-20需求五之dws层开发.mp4
┣━[3.5.5.22]–5-22需求五之结果验证.mp4
┣━[3.5.5.5]–5-5用户行为数据数仓需求分析.mp4
┣━[3.5.5.16]–5-16需求四之需求分析.mp4
┣━[3.5.5.17]–5-17需求四之app层开发.mp4
┣━[3.5.5.18]–5-18需求四之开发脚本.mp4
┣━[3.5.5.24]–5-24需求六之dws层和app层开发.mp4
┣━[3.5.5.25]–5-25需求六之开发脚本.mp4
┣━[3.5.5.3]–5-3用户行为数据数仓开发之dwd层开发.mp4
┣━[3.5.5.9]–5-9需求一之开发脚本.mp4
┣━{6}–第6章项目核心复盘
┣━[3.5.6.1]–6-1本周总结.mp4
┣━{6}–综合项目:电商数据仓库之商品订单数仓
┣━{1}–第1章商品订单数仓需求分析
┣━[3.6.1.1]–1-1商品订单数据数仓开发之ods层和dwd层.mp4
┣━[3.6.1.2]–1-2商品订单数据数仓需求分析.mp4
┣━{2}–第2章需求设计与实现
┣━[3.6.2.5]–2-5需求二之app层开发.mp4
┣━[3.6.2.3]–2-3需求一之开发脚本.mp4
┣━[3.6.2.4]–2-4需求二之需求分析.mp4
┣━[3.6.2.9]–2-9需求三之开发脚本.mp4
┣━[3.6.2.11]–2-11需求四之app层开发.mp4
┣━[3.6.2.2]–2-2需求一之dws层开发.mp4
┣━[3.6.2.6]–2-6需求二之开发脚本.mp4
┣━[3.6.2.7]–2-7需求三之需求分析.mp4
┣━[3.6.2.8]–2-8需求三之dws层和app层开发.mp4
┣━[3.6.2.10]–2-10需求四之需求分析.mp4
┣━[3.6.2.12]–2-12需求四之开发脚本.mp4
┣━[3.6.2.1]–2-1需求一之需求分析.mp4
┣━{3}–第3章订单拉链表实战
┣━[3.6.3.2]–3-2如何制作拉链表.mp4
┣━[3.6.3.3]–3-3【实战】基于订单表的拉链表实现-1.mp4
┣━[3.6.3.4]–3-4【实战】基于订单表的拉链表实现-2.mp4
┣━[3.6.3.5]–3-5【实战】基于订单表的拉链表实现-3.mp4
┣━[3.6.3.6]–3-6拉链表的性能问题分析.mp4
┣━[3.6.3.1]–3-1什么是拉链表.mp4
┣━[3.6.3.7]–3-7商品订单数据数仓表和任务脚本总结.mp4
┣━{4}–第4章数据可视化和任务调度实现
┣━[3.6.4.2]–4-2数据可视化之Zepplin的使用.mp4
┣━[3.6.4.8]–4-8项目优化.mp4
┣━[3.6.4.3]–4-3任务调度之Crontab调度器的使用.mp4
┣━[3.6.4.5]–4-5任务调度之Azkaban提交独立任务.mp4
┣━[3.6.4.7]–4-7任务调度之在数仓中使用Azkaban.mp4
┣━[3.6.4.4]–4-4任务调度之Azkaban的安装部署.mp4
┣━[3.6.4.6]–4-6任务调度之Azkaban提交依赖任务.mp4
┣━[3.6.4.1]–4-1数据可视化之Zepplin的安装部署和参数配置.mp4
┣━{5}–第5章项目核心复盘
┣━[3.6.5.1]–5-1本周总结.mp4
┣━{6}–第6章数据压缩格式和存储格式在数仓中的应用
┣━[3.6.6.1]–6-1数据存储格式和压缩格式在数仓中的应用.mp4
┣━{4}–阶段四:高频实时数据处理+海量数据全文检索方案
┣━{1}–消息队列之Kafka从入门到小牛
┣━{1}–第1章初识Kafka
┣━[4.1.1.2]–1-2什么是Kafka.mp4
┣━[4.1.1.1]–1-1什么是消息队列.mp4
┣━{2}–第2章Kafka集群安装部署
┣━[4.1.2.3]–2-3Kafka安装部署之单机模式.mp4
┣━[4.1.2.2]–2-2Zookeeper安装部署之集群模式.mp4
┣━[4.1.2.4]–2-4Kafka安装部署之集群模式.mp4
┣━[4.1.2.1]–2-1Zookeeper安装部署之单机模式.mp4
┣━{3}–第3章Kafka使用初体验
┣━[4.1.3.1]–3-1Kafka中Topic的操作.mp4
┣━[4.1.3.2]–3-2Kafka中的生产者和消费者.mp4
┣━[4.1.3.3]–3-3案例:QQ群聊天.mp4
┣━{4}–第4章Kafka核心扩展内容
┣━[4.1.4.2]–4-2Producer扩展内容.mp4
┣━[4.1.4.1]–4-1Broker扩展内容.mp4
┣━{5}–第5章Kafka核心之存储和容错机制
┣━[4.1.5.1]–5-1Topic+Partition+Message扩展内容.mp4
┣━[4.1.5.2]–5-2存储策略.mp4
┣━[4.1.5.3]–5-3容错机制.mp4
┣━{6}–第6章Kafka生产消费者实战
┣━[4.1.6.1]–6-1Java代码实现生产者代码.mp4
┣━[4.1.6.2]–6-2Java代码实现消费者代码.mp4
┣━[4.1.6.4]–6-4Consumer消费Offset查询.mp4
┣━[4.1.6.5]–6-5Consumer消费顺序.mp4
┣━[4.1.6.3]–6-3消费者代码扩展.mp4
┣━[4.1.6.6]–6-6Kafka的三种语义.mp4
┣━{7}–第7章Kafka技巧篇
┣━[4.1.7.1]–7-1JVM参数调忧.mp4
┣━[4.1.7.2]–7-2Replication参数调忧.mp4
┣━[4.1.7.5]–7-5Kafka集群监控管理工具(CMAK).mp4
┣━[4.1.7.4]–7-4KafkaTopic命名小技巧.mp4
┣━[4.1.7.3]–7-3Log参数调忧.mp4
┣━{8}–第8章Kafka小试牛刀实战篇
┣━[4.1.8.3]–8-3实战:Kafka集群平滑升级.mp4
┣━[4.1.8.1]–8-1实战:Flume集成Kafka-1.mp4
┣━[4.1.8.2]–8-2实战:Flume集成Kafka-2.mp4
┣━{9}–第9章Kafka核心复盘
┣━[4.1.9.1]–9-1本周总结+寄语.mp4
┣━{2}–极速上手内存数据库Redis
┣━{1}–第1章快速了解Redis
┣━[4.2.1.3]–1-3Redis基础命令.mp4
┣━[4.2.1.4]–1-4Redis多数据库特性.mp4
┣━[4.2.1.1]–1-1快速了解Redis.mp4
┣━[4.2.1.2]–1-2Redis的安装部署.mp4
┣━{2}–第2章Redis核心实践
┣━[4.2.2.1]–2-1Redis常用数据类型之String.mp4
┣━[4.2.2.3]–2-3Redis常用数据类型之List.mp4
┣━[4.2.2.4]–2-4Redis常用数据类型之Set.mp4
┣━[4.2.2.5]–2-5Redis常用数据类型之SortedSet.mp4
┣━[4.2.2.2]–2-2Redis常用数据类型之Hash.mp4
┣━{3}–第3章Redis封装工具类技巧
┣━[4.2.3.1]–3-1Java代码操作Redis之单连接.mp4
┣━[4.2.3.3]–3-3提取RedisUtils工具类.mp4
┣━[4.2.3.2]–3-2Java代码操作Redis之连接池.mp4
┣━{4}–第4章Redis高级特性
┣━[4.2.4.4]–4-4Redis持久化之AOF.mp4
┣━[4.2.4.1]–4-1Redis高级特性之expire.mp4
┣━[4.2.4.5]–4-5Redis的安全策略.mp4
┣━[4.2.4.2]–4-2Redis高级特性之pipeline和info.mp4
┣━[4.2.4.3]–4-3Redis持久化之RDB.mp4
┣━[4.2.4.6]–4-6Redis监控命令-monitor.mp4
┣━{5}–第5章Redis核心复盘
┣━[4.2.5.1]–5-1Redis架构演进过程.mp4
┣━[4.2.5.2]–5-2本周总结+寄语.mp4
┣━{3}–Flink快速上手篇
┣━{1}–第1章初识Flink
┣━[4.3.1.1]–1-1快速了解Flink.mp4
┣━{2}–第2章实战:流处理和批处理程序开发
┣━[4.3.2.2]–2-2FlinkStreaming程序开发-Java.mp4
┣━[4.3.2.3]–2-3FlinkBatch程序开发-Scala.mp4
┣━[4.3.2.4]–2-4FlinkBatch程序开发-Java.mp4
┣━{3}–第3章Flink集群安装部署
┣━[4.3.3.1]–3-1FlinkStandalone集群安装部署.mp4
┣━[4.3.3.2]–3-2FlinkONYARN的两种方式.mp4
┣━[4.3.3.3]–3-3向集群中提交Flink任务.mp4
┣━{4}–第4章Flink核心API之DataStreamAPI
┣━[4.3.4.1]–4-1Flink核心API介绍.mp4
┣━[4.3.4.5]–4-5DataStreamAPI之Transformation-.mp4
┣━[4.3.4.7]–4-7DataStreamAPI之Transformation-.mp4
┣━[4.3.4.4]–4-4DataStreamAPI之Transformation-.mp4
┣━[4.3.4.6]–4-6DataStreamAPI之Transformation-.mp4
┣━[4.3.4.8]–4-8DataStreamAPI之Transformation-.mp4
┣━[4.3.4.2]–4-2DataStreamAPI之DataSource.mp4
┣━[4.3.4.3]–4-3DataStreamAPI之Transformation-.mp4
┣━[4.3.4.9]–4-9DataStreamAPI之DataSink.mp4
┣━{5}–第5章Flink核心API之DataSetAPI
┣━[4.3.5.3]–5-3DataSetAPI之Transformation-out.mp4
┣━[4.3.5.4]–5-4DataSetAPI之Transformation-cro.mp4
┣━[4.3.5.5]–5-5DataSetAPI之Transformation-fir.mp4
┣━[4.3.5.2]–5-2DataSetAPI之Transformation-joi.mp4
┣━[4.3.5.1]–5-1DataSetAPI之Transformation-map.mp4
┣━{6}–第6章Flink核心API之TableAPI和SQL
┣━[4.3.6.3]–6-3TableAPI和SQL的使用.mp4
┣━[4.3.6.7]–6-7将表转换成DataSet.mp4
┣━[4.3.6.1]–6-1TableAPI和SQL介绍.mp4
┣━[4.3.6.2]–6-2创建TableEnvironment对象.mp4
┣━[4.3.6.4]–6-4使用DataStream创建表.mp4
┣━[4.3.6.5]–6-5使用DataSet创建表.mp4
┣━{7}–第7章Flink核心复盘
┣━[4.3.7.1]–7-1本周总结+寄语.mp4
┣━{4}–Flink高级进阶之路
┣━{1}–第1章Flink中的Window和Time详解
┣━[4.4.1.1]–1-1Window的概念和类型.mp4
┣━[4.4.1.3]–1-3CountWindow的使用.mp4
┣━[4.4.1.2]–1-2TimeWindow的使用.mp4
┣━[4.4.1.4]–1-4自定义Window的使用.mp4
┣━[4.4.1.5]–1-5Window中的增量聚合和全量聚合.mp4
┣━[4.4.1.6]–1-6Flink中的Time.mp4
┣━{2}–第2章Flink中的Watermark深入剖析
┣━[4.4.2.2]–2-2开发Watermark代码.mp4
┣━[4.4.2.5]–2-5Watermark+EventTime处理乱序数据.mp4
┣━[4.4.2.6]–2-6延迟数据的三种处理方式.mp4
┣━[4.4.2.1]–2-1Watermark的分析.mp4
┣━[4.4.2.3]–2-3开发Watermark代码.mp4
┣━{3}–第3章Flink中的并行度详解
┣━[4.4.3.1]–3-1并行度介绍及四种设置方式.mp4
┣━[4.4.3.2]–3-2并行度案例分析.mp4
┣━{4}–第4章Flink之KafkaConnector专题
┣━[4.4.4.5]–4-5KafkaProducer的容错.mp4
┣━[4.4.4.4]–4-4KafkaProducer的使用.mp4
┣━[4.4.4.2]–4-2KafkaConsumer消费策略设置.mp4
┣━[4.4.4.3]–4-3KafkaConsumer的容错.mp4
┣━{5}–第5章SparkStreaming快速上手
┣━[4.4.5.2]–5-2SparkStreaming整合Kafka.mp4
┣━{6}–第6章Flink核心复盘
┣━[4.4.6.1]–6-1本周总结+寄语.mp4
┣━{7}–第7章【福利加油站】
┣━[4.4.7.4]–7-4【加餐】双11大屏指标核心代码开发-2.mp4
┣━[4.4.7.5]–7-5【加餐】双11大屏从0~1全流程跑通.mp4
┣━[4.4.7.1]–7-1【加餐】天猫双11大屏的由来.mp4
┣━[4.4.7.2]–7-2【加餐】双11大屏需求分析及架构设计.mp4
┣━[4.4.7.3]–7-3【加餐】双11大屏指标核心代码开发-1.mp4
┣━{5}–Flink1.15新特性及状态的使用
┣━{2}–第2章快速上手使用Flink1.15
┣━[4.5.2.1]–2-1开发Flink1.15版本批流一体化代码.mp4
┣━[4.5.2.2]–2-2在已有的大数据集群中集成Flink1.15版本的环境.mp4
┣━{3}–第3章State(状态)的使用与管理
┣━[4.5.3.11]–3-11OperatorState原理分析.mp4
┣━[4.5.3.6]–3-6KeyedState案例之温度告警(ValueState).mp4
┣━[4.5.3.7]–3-7KeyedState案例之直播间数据统计(MapState.mp4
┣━[4.5.3.10]–3-10KeyedState的使用形式总结.mp4
┣━[4.5.3.12]–3-12OperatorState案例之ListState的使用.mp4
┣━[4.5.3.14]–3-14OperatorState案例之BroadcastSta.mp4
┣━[4.5.3.15]–3-15OperatorState案例之BroadcastSta.mp4
┣━[4.5.3.2]–3-2State相关概念整体概览.mp4
┣━[4.5.3.3]–3-3State(状态)的类型介绍.mp4
┣━[4.5.3.4]–3-4KeyedState原理分析.mp4
┣━[4.5.3.5]–3-5KeyedState案例之温度告警(ValueState).mp4
┣━[4.5.3.13]–3-13OperatorState案例之UnionListSta.mp4
┣━[4.5.3.8]–3-8KeyedState案例之订单数据补全(ListState.mp4
┣━[4.5.3.1]–3-1什么是State(状态).mp4
┣━[4.5.3.9]–3-9KeyedState案例之订单数据补全(ListState.mp4
┣━{6}–Flink1.15之状态的容错与一致性
┣━{1}–第1章State(状态)的容错与一致性
┣━[4.6.1.10]–1-10从Savepoint进行恢复之正常恢复.mp4
┣━[4.6.1.11]–1-11从Savepoint进行恢复之异常恢复(上).mp4
┣━[4.6.1.15]–1-15Window中的数据存在哪里.mp4
┣━[4.6.1.2]–1-2如何实现Flink任务的端到端一致性.mp4
┣━[4.6.1.3]–1-3Checkpoint机制的原理及核心配置.mp4
┣━[4.6.1.5]–1-5从Checkpoint进行恢复-手动恢复.mp4
┣━[4.6.1.7]–1-7Savepoint详解之算子唯一标识.mp4
┣━[4.6.1.12]–1-12从Savepoint进行恢复之异常恢复(下).mp4
┣━[4.6.1.13]–1-13StateBackend的原理及配置.mp4
┣━[4.6.1.14]–1-14State的生存时间的原理及使用.mp4
┣━[4.6.1.1]–1-1State的容错与一致性介绍.mp4
┣━[4.6.1.6]–1-6从Checkpoint进行恢复-自动恢复.mp4
┣━[4.6.1.8]–1-8Savepoint详解之算子最大并行度.mp4
┣━[4.6.1.9]–1-9手工触发Savepoint.mp4
┣━[4.6.1.4]–1-4保存多个Checkpoint.mp4
┣━{2}–第2章Checkpoint与State底层原理深度剖析
┣━[4.6.2.2]–2-2CheckpointBarrier原理分析.mp4
┣━[4.6.2.3]–2-3Kafka+Flink+Kafka实现端到端一致性.mp4
┣━[4.6.2.1]–2-1Checkpoint的生成和恢复过程.mp4
┣━[4.6.2.4]–2-4Flink+Kafka相关源码分析.mp4
┣━{3}–第3章Kafka-connector新API的使用
┣━[4.6.3.2]–3-2KafkaSource实战应用.mp4
┣━[4.6.3.3]–3-3KafkaSink源码分析.mp4
┣━[4.6.3.4]–3-4KafkaSink实战应用.mp4
┣━[4.6.3.5]–3-5KafkaSink开启Checkpoint时的数据延迟问题.mp4
┣━{7}–全文检索引擎Elasticsearch
┣━{1}–第1章快速了解Elasticsearch
┣━[4.7.1.1]–1-1Elasticsearch简介.mp4
┣━[4.7.1.2]–1-2MySQLVSElasticsearch.mp4
┣━[4.7.1.3]–1-3Elasticsearch核心概念.mp4
┣━{2}–第2章快速上手使用Elasticsearch
┣━[4.7.2.4]–2-4Elasticsearch集群监控管理工具-cerebro.mp4
┣━[4.7.2.6]–2-6使用RestAPI的方式操作ES的索引.mp4
┣━[4.7.2.7]–2-7使用JavaAPI的方式操作ES的索引库.mp4
┣━[4.7.2.3]–2-3Elasticsearch集群安装步骤.mp4
┣━[4.7.2.2]–2-2Elasticsearch单机安装步骤.mp4
┣━[4.7.2.1]–2-1Elasticsearch安装包配置文件分析.mp4
┣━[4.7.2.5]–2-5使用RestAPI的方式操作ES的索引库.mp4
┣━[4.7.2.8]–2-8使用JavaAPI的方式操作ES的索引.mp4
┣━{3}–第3章Elasticsearch分词详解
┣━[4.7.3.4]–3-9Elasticsearch添加热更新词库.mp4
┣━[4.7.3.3]–3-8Elasticsearch添加自定义词库.mp4
┣━[4.7.3.1]–3-1Elasticsearch分词及倒排索引介绍.mp4
┣━[4.7.3.2]–3-7Elasticsearch集成中文分词插件(es-ik).mp4
┣━{4}–第4章Elasticsearch查询详解
┣━[4.7.4.2]–4-3Elasticsearchquery过滤功能-1.mp4
┣━[4.7.4.3]–4-4Elasticsearchquery过滤功能-2.mp4
┣━[4.7.4.4]–4-5Elasticsearch分页+排序功能.mp4
┣━[4.7.4.7]–4-10Elasticsearch聚合案例-2.mp4
┣━[4.7.4.8]–4-11Elasticsearch获取所有分组数据.mp4
┣━[4.7.4.1]–4-1ElasticsearchSearch查询.mp4
┣━[4.7.4.5]–4-6Elasticsearch高亮功能.mp4
┣━{5}–第5章Elasticsearch的高级特性
┣━[4.7.5.3]–5-3Elasticsearch的偏好查询.mp4
┣━[4.7.5.2]–5-2Elasticsearch中的mapping.mp4
┣━[4.7.5.5]–5-7ElasticsearchSQL的使用.mp4
┣━[4.7.5.1]–5-1Elasticsearch中的settings.mp4
┣━[4.7.5.4]–5-4Elasticsearch的routing路由功能.mp4
┣━{8}–Es+HBase仿百度搜索引擎项目
┣━{1}–第1章企业中快速复杂查询痛点分析
┣━[4.8.1.1]–1-1企业中快速复杂查询痛点分析.mp4
┣━{2}–第2章仿百度搜索引擎项目架构设计
┣━[4.8.2.1]–2-1仿百度搜索引擎项目架构设计.mp4
┣━{3}–第3章ES高级特性扩展
┣━[4.8.3.2]–3-2ES高级特性案例实操.mp4
┣━[4.8.3.1]–3-1ES高级特性原理分析.mp4
┣━{4}–第4章开发仿百度搜索引擎项目
┣━[4.8.4.5]–4-5通过ES对HBase中的数据建立索引-2.mp4
┣━[4.8.4.6]–4-6对接Web项目实现核心检索代码.mp4
┣━[4.8.4.7]–4-7从0~1运行项目.mp4
┣━[4.8.4.1]–4-1项目需求和开发步骤分析.mp4
┣━[4.8.4.2]–4-2获取接口数据导入HBase和Redis-1.mp4
┣━[4.8.4.4]–4-4通过ES对HBase中的数据建立索引-1.mp4
┣━[4.8.4.3]–4-3获取接口数据导入HBase和Redis-2.mp4
┣━{5}–阶段五:综合项目:三度关系推荐系统+数据中台
┣━{1}–直播平台三度关系推荐V1.0
┣━{1}–第1章项目介绍及演示
┣━[5.1.1.1]–1-1项目介绍.mp4
┣━{2}–第2章项目技术选型
┣━[5.1.2.2]–2-2技术选型之数据存储.mp4
┣━[5.1.2.3]–2-3技术选型之数据计算+数据展现.mp4
┣━[5.1.2.4]–2-4项目整体架构设计.mp4
┣━[5.1.2.1]–2-1技术选型之数据采集.mp4
┣━{3}–第3章Neo4j图数据库快速上手使用
┣━[5.1.3.5]–3-5Neo4j之建立索引+批量导入数据.mp4
┣━[5.1.3.2]–3-2Neo4j之添加数据.mp4
┣━[5.1.3.3]–3-3Neo4j之查询数据.mp4
┣━[5.1.3.1]–3-1Neo4j介绍及安装部署.mp4
┣━[5.1.3.4]–3-4Neo4j之更新数据.mp4
┣━{4}–第4章数据采集模块分析
┣━[5.1.4.1]–4-1数据采集架构详细设计.mp4
┣━[5.1.4.2]–4-2数据来源分析.mp4
┣━[5.1.4.3]–4-3模拟产生数据.mp4
┣━{5}–第5章数据采集+聚合+分发+落盘
┣━[5.1.5.1]–5-1数据采集聚合.mp4
┣━[5.1.5.4]–5-4采集服务端数据库数据.mp4
┣━[5.1.5.3]–5-3数据落盘.mp4
┣━[5.1.5.2]–5-2数据分发.mp4
┣━{6}–第6章数据计算核心指标分析
┣━[5.1.6.1]–6-1数据计算核心指标详细分析.mp4
┣━{7}–第7章数据核心指标计算
┣━[5.1.7.10]–7-10数据计算之每周一计算三度关系推荐列表数据-2.mp4
┣━[5.1.7.2]–7-2数据计算之实时维护粉丝关注数据-1.mp4
┣━[5.1.7.5]–7-5数据计算之每天定时更新主播等级.mp4
┣━[5.1.7.7]–7-7数据计算之每周一计算最近一个月主播视频评级-1.mp4
┣━[5.1.7.9]–7-9数据计算之每周一计算三度关系推荐列表数据-1.mp4
┣━[5.1.7.3]–7-3数据计算之实时维护粉丝关注数据-2.mp4
┣━[5.1.7.6]–7-6数据计算之每天定时更新用户活跃时间.mp4
┣━[5.1.7.1]–7-1数据计算之历史粉丝关注数据初始化.mp4
┣━[5.1.7.4]–7-4数据计算之实时维护粉丝关注数据-3.mp4
┣━[5.1.7.11]–7-11三度关系数据导出到MySQL.mp4
┣━{8}–第8章项目核心复盘
┣━[5.1.8.1]–8-1总结(三度关系推荐系统V1.0).mp4
┣━{2}–直播平台三度关系推荐V2.0
┣━{1}–第1章V1.0架构方案分析及V2.0架构设计
┣━[5.2.1.1]–1-1V1.0架构问题分析及V2.0架构设计.mp4
┣━{2}–第2章V2.0架构之数据核心指标计算
┣━[5.2.2.10]–2-10数据计算之每周一计算三度关系列表-3.mp4
┣━[5.2.2.1]–2-1数据计算之历史粉丝关注数据初始化.mp4
┣━[5.2.2.2]–2-2数据计算之实时维护粉丝关注数据-1.mp4
┣━[5.2.2.4]–2-4数据计算之每天定时更新主播等级.mp4
┣━[5.2.2.7]–2-7数据计算之每周一计算最近一个月主播视频评级-2.mp4
┣━[5.2.2.3]–2-3数据计算之实时维护粉丝关注数据-2.mp4
┣━[5.2.2.6]–2-6数据计算之每周一计算最近一个月主播视频评级-1.mp4
┣━[5.2.2.11]–2-11数据计算之三度关系列表数据导出到Redis.mp4
┣━[5.2.2.5]–2-5数据计算之每天更新用户活跃时间.mp4
┣━[5.2.2.8]–2-8数据计算之每周一计算三度关系列表-1.mp4
┣━[5.2.2.9]–2-9数据计算之每周一计算三度关系列表-2.mp4
┣━{3}–第3章数据接口定义及开发
┣━[5.2.3.1]–3-1数据接口定义及开发.mp4
┣━{4}–第4章数据展示
┣━[5.2.4.1]–4-1数据展示.mp4
┣━{5}–第5章项目扩展优化
┣━[5.2.5.2]–5-2项目数据规模及集群规模相关指标分析.mp4
┣━[5.2.5.1]–5-1项目中遇到的问题及优化.mp4
┣━{6}–第6章项目核心复盘
┣━[5.2.6.1]–6-1总结(三度关系推荐系统V2.0).mp4
┣━{3}–数据中台大屏
┣━{1}–第1章数据中台的前世今生
┣━[5.3.1.1]–1-1什么是中台.mp4
┣━{2}–第2章数据中台架构
┣━[5.3.2.1]–2-1什么是数据中台.mp4
┣━[5.3.2.2]–2-2数据中台架构.mp4
┣━{3}–第3章什么样的企业适合建设数据中台
┣━[5.3.3.1]–3-1什么样的企业适合建设数据中台.mp4
┣━{4}–第4章数据中台企业级解决方案
┣━[5.3.4.1]–4-1企业级数据中台架构分析.mp4
┣━{5}–第5章项目总结
┣━[5.3.5.1]–5-1总结.mp4
┣━{6}–第6章数据中台之数据加工总线
┣━[5.3.6.1]–6-1快速了解数据加工总线.mp4
┣━{7}–第7章数据加工总线之SparkSQL计算引擎开发
┣━[5.3.7.11]–7-11使用RestAPI向YARN集群提交任务(1).mp4
┣━[5.3.7.12]–7-12使用RestAPI向YARN集群提交任务(2).mp4
┣━[5.3.7.2]–7-2开发基于SparkSQL的通用计算引擎(1).mp4
┣━[5.3.7.10]–7-10支持自定义函数返回多列字段.mp4
┣━[5.3.7.13]–7-13使用RestAPI向YARN集群提交任务(3).mp4
┣━[5.3.7.5]–7-5开发基于SparkSQL的通用计算引擎(4).mp4
┣━[5.3.7.6]–7-6验证SparkSQL计算引擎代码.mp4
┣━[5.3.7.14]–7-14使用RestAPI向YARN集群提交任务(4).mp4
┣━[5.3.7.1]–7-1核心功能点梳理.mp4
┣━[5.3.7.3]–7-3开发基于SparkSQL的通用计算引擎(2).mp4
┣━[5.3.7.7]–7-7封装正式的SparkSQL计算引擎代码.mp4
┣━[5.3.7.8]–7-8支持复杂字段类型:数组.mp4
┣━{8}–第8章数据加工总线之FlinkSQL计算引擎开发
┣━[5.3.8.1]–8-1增加底层计算引擎FlinkSQL.mp4
┣━{9}–第9章后期展望
┣━[5.3.9.1]–9-1后期展望.mp4
┣━大数据课件
┣━PDF课件
┣━10、数据仓库之Hive.pdf
┣━11、Hive扩展内容2022.pdf
┣━12、NoSQL列式存储数据库之HBASE.pdf
┣━13、数据分析引擎之Impala.pdf
┣━14、Scala快速上手.pdf
┣━15、内存计算引擎之Spark.pdf
┣━16、内存计算引擎之Spark.pdf
┣━17、Spark 3.x 版本扩展.pdf
┣━18、用户行为数仓.pdf
┣━19、电商数据仓库项目.pdf
┣━1、linux快速上手应用.pdf
┣━20、商品订单数仓.pdf
┣━21、电商数据仓库项目.pdf
┣━22、消息队列之Kafka.pdf
┣━23、NoSQL内存数据库之Redis.pdf
┣━24、新一代计算引擎之Flink.pdf
┣━25、FlinkWatermark详解.pdf
┣━26、新一代计算引擎之Flink.pdf
┣━27、Flink1.15 版本扩展.pdf
┣━28、Flink1.15 版本扩展.pdf
┣━29、Flink sql快速上手使用.pdf
┣━2、大数据起源之Hadoop.pdf
┣━30、全文检索引擎Elasticsearch.pdf
┣━31、ES HBase实现仿百度搜索引擎.pdf
┣━32、直播平台三度关系推荐系统V1.0.pdf
┣━33、直播平台三度关系推荐系统V2.0.pdf
┣━34、数据中台大屏.pdf
┣━35、数据中台之数据加工总线.pdf
┣━35份课件截图.png
┣━3、大数据起源之Hadoop.pdf
┣━4、Hadoop扩展内容.pdf
┣━5、大数据起源之Hadoop.pdf
┣━6、Hadoop扩展内容.pdf
┣━7、大数据起源之Hadoop.pdf
┣━8、大数据起源之Hadoop.pdf
┣━9、数据采集之Flume.pdf
┣━作业和讨论
┣━100、【学习任务】项目任务-使用Java代码开发SparkSQL计算引擎代码.txt
┣━101、【学习任务】项目任务-开发基于SparkSQL的通用离线计算引擎.txt
┣━102、【学习任务】项目任务–使用Java代码开发FlinkSQL计算引擎代码.txt
┣━103、【学习任务】项目任务–开发基于FlinkSQL的通用离线计算引擎.txt
┣━10、【讨论题】HDFS集群之间是否可以实现数据迁移?.txt
┣━11、【学习任务】项目任务-获取HDFS指定路径下所有文件的Block块信息.txt
┣━12、如何通过JS代码获取HDFS中的文件信息?.txt
┣━13、【讨论题】Hadoop中必须要有SecondaryNameNode进程吗?.txt
┣━14、【学习任务】项目任务-定时下载HDFS中的日志文件.txt
┣━15、【讨论题】HDFS中的安全模式有什么意义?.txt
┣━16、【讨论题】HDFS中NameNode内存将要耗尽,有什么解决方案?.txt
┣━17、【讨论题】如何查找HDFS中的大文件?.txt
┣━18、【讨论题】MR中的Combiner阶段在什么场景下适合使用?.txt
┣━19、【学习任务】项目任务-使用MapReduce开发自定义二次排序Key.txt
┣━1、【讨论题】如何查找Linux中的大文件?.txt
┣━20、【学习任务】项目任务-使用MapReduce实现TopN的需求.txt
┣━21、【讨论题】能不能使用zip或者rar文件解决HDFS中的小文件问题?.txt
┣━22、【讨论题】如何从一批数据中找出倾斜的key?.txt
┣━23、【学习任务】项目任务-在MapReduce程序中使用gzip数据压缩提高计.txt
┣━24、【学习任务】项目任务-在MapReduce程序中同时处理多个输入目录.txt
┣━25、【讨论题】分析一下Hadoop中的RPC框架?.txt
┣━26、【学习任务】项目任务-在Flume中自定义Sink组件.txt
┣━27、【讨论题】Flume中哪些地方用到事务机制?.txt
┣━28、【讨论题】Flume、FileBeat和Logstash三者的区别?.txt
┣━29、【讨论题】生产环境中为什么建议使用Hive外部表?.txt
┣━2、【学习任务】项目任务-分析论坛访问日志.txt
┣━30、【讨论题】Hive分区表如何开启自动加载分区?.txt
┣━31、【讨论题】分析Hive中数据的序列化格式?.txt
┣━32、【学习任务】项目任务-开发自定义SQL函数实现单词首字母大写转换.txt
┣━33、【学习任务】项目任务-使用SQL统计销售数据.txt
┣━34、【学习任务】项目任务-SQL优化.txt
┣━35、【学习任务】项目任务-使用HiveSQL发现倾斜的Key.txt
┣━36、【学习任务】项目任务-使用Hive加载指定格式数据.txt
┣━37、【讨论题】分析一下map和tuple 的区别?.txt
┣━38、【学习任务】项目任务-使用Scala读取MySQL数据库中的数据.txt
┣━39、【学习任务】项目任务-使用Scala实现单例设计模式.txt
┣━3、【讨论题】为什么使用jps命令查看不到正在运行的Java进程?.txt
┣━40、【讨论题】谈一下你对Scala和Java的认知?.txt
┣━41、【讨论题】Scala中的下划线 _ 有哪些作用?.txt
┣━42、【讨论题】谈一谈你对Spark框架的使用感受?.txt
┣━43、【学习任务】项目任务-Spark实现多路输出.txt
┣━44、【讨论题】Spark中join和cogroup的区别?.txt
┣━45、【讨论题】Spark如何读取多个不同目录下的数据(多路输入).txt
┣━46、【学习任务】项目任务-对WordCount的结果排序输出.txt
┣━47、【学习任务】项目任务-使用Spark开发自定义二次排序Key.txt
┣━48、【讨论题】介绍一下Spark的远程进程通信机制?.txt
┣━49、【讨论题】Spark中的repartition和coalesce有什么区别?.txt
┣━4、【学习任务】项目任务-杀掉某挖矿程序.txt
┣━50、【学习任务】项目任务-在SparkSQL中使用自定义函数(UDF).txt
┣━51、【讨论题】谈一下你对SparkSQL和Hive的理解?.txt
┣━52、【讨论题】分析一下SparkSQL的执行流程.txt
┣━53、【讨论题】什么是数据湖?.txt
┣━54、【学习任务】项目任务-Sqoop将MySQL表数据导入Hive表中.txt
┣━55、【学习任务】项目任务-Sqoop将Hive表数据导出到MySQL表中.txt
┣━56、【讨论题】Sqoop将Hive数据导出到MySQL有哪些种方式?.txt
┣━57、【讨论题】在开发数仓脚本的时候都有哪些注意事项?.txt
┣━58、【学习任务】项目任务-使用Spark代码实现ods层数据清洗.txt
┣━59、【讨论题】谈一谈你对拉链表的理解?.txt
┣━5、【讨论题】如何确认Crontab中的定时任务是否正常执行?.txt
┣━60、【学习任务】项目任务-使用Azkaban调度漏斗分析需求相关任务.txt
┣━61、【讨论题】谈一下你对Ooize的看法.txt
┣━62、【学习任务】项目任务-Zookeeper实现分布式进程监控.txt
┣━63、【讨论题】Zookeeper如何实现分布式共享.txt
┣━64、【学习任务】项目任务-开发Topic Offset智能监控工具.txt
┣━65、【学习任务】项目任务-开发消费者待消费数据(lag)监控告警工具.txt
┣━66、【讨论题】如何保证Kafka数据不丢失?.txt
┣━67、【讨论题】kafka如何保证数据一致性和可靠性.txt
┣━68、【讨论题】谈一谈你对Kafka中exactly-once语义的理解.txt
┣━69、【学习任务】项目任务-使用Redis实现一个带有优先级的先进先出队.txt
┣━6、【学习任务】项目任务-使用shell脚本一键安装配置JDK.txt
┣━70、【学习任务】项目任务-使用Scala代码实现RedisUtils工具类.txt
┣━71、【讨论题】Redis中事务和管道的区别.txt
┣━72、【讨论题】如何查看Redis中的数据使用了多少内存.txt
┣━73、【讨论题】Redis的内存碎片问题.txt
┣━74、【学习任务】项目任务-Redis在排行榜中的使用.txt
┣━75、【学习任务】项目任务-在Flink流计算中开发自定义Source.txt
┣━76、【学习任务】项目任务-在Flink流计算中开发自定义Sink.txt
┣━77、【学习任务】项目任务-在Flink批处理中创建自定义Source.txt
┣━78、【学习任务】项目任务-在Flink批处理中创建自定义Sink.txt
┣━79、【讨论题】Flink中的哪些算子容易产生数据倾斜.txt
┣━7、【讨论题】企业应该如何选择Hadoop发行版?.txt
┣━80、【讨论题】Flink SQL的 执行流程.txt
┣━81、【学习任务】项目任务-FlinkSQL和Kafka的集成.txt
┣━82、【学习任务】项目任务-在SparkStreaming中使用SparkSQL.txt
┣━83、【讨论题】如果让你设计架构,你会如何设计?.txt
┣━84、【学习任务】项目任务-实时维护粉丝关注数据-Java代码实现.txt
┣━85、【学习任务】项目任务-实时粉丝关注数据乱序问题.txt
┣━86、【学习任务】项目任务-每天定时更新主播等级-Java代码实现.txt
┣━87、【学习任务】项目任务-每天定时更新用户活跃时间-Java代码实现.txt
┣━88、【学习任务】项目任务-每周一计算最近一个月主播视频评级-Java代.txt
┣━89、【学习任务】项目任务-每周一计算三度关系推荐列表数据-Java代码.txt
┣━8、【学习任务】项目任务-安装配置Hadoop客户端节点.txt
┣━90、【学习任务】项目任务-使用Spark代码实现三度关系列表数据导出My.txt
┣━91、【讨论题目】如果是你,你会如何优化架构?.txt
┣━92、【学习任务】项目任务-实时维护粉丝关注数据-Java代码实现.txt
┣━93、【学习任务】项目任务-每天定时更新主播等级-Java代码实现.txt
┣━94、【学习任务】项目任务-每天定时更新用户活跃时间-Java代码实现.txt
┣━95、【学习任务】项目任务-每周一计算最近一个月主播视频评级-Java代.txt
┣━96、【学习任务】项目任务-每周一计算三度关系列表-Java代码实现.txt
┣━97、【学习任务】项目任务-使用Flinkk代码实现三度关系列表数据导出.txt
┣━98、【讨论题目】 针对目前Neo4j中的数据,哪些属性需要建建立索引.txt
┣━99、【讨论题目】 谈一谈你对数据中台的理解.txt
┣━9、【讨论题】Hadoop客户端节点是怎么识别Hadoop集群的?.txt
┣━access(测试数据).log
┣━接口数据集
┣━data.sql
┣━GenerateGoodsOrderData.sql
┣━GenerateUserActionData.json
┣━GenerateZipData.json
┣━666JAVA下载必看
┣━看看我【www.dbbp.net】.zip
┣━课程总结.mp4
┣━资料2.zip
┣━软件下载.txt
┣━高薪学习it网.url
┣━下载必看.txt
┣━海量优质it资源【www.dbbp.net】.url
┣━面试合集.txt
┣━解压密码:666java.com
┣━电子书
┣━HDFS HA安装部署文档
┣━HDFS HA安装部署文档.docx
┣━【附送】选学内容
┣━3 Hadoop 3.0新特性之纠删码技术.mhtml
┣━1 Hive on Tez 引擎配置_.mhtml
┣━2 CDH6.2大数据平台安装部署.mhtml
┣━第10周-快速上手NoSQL数据库HBase
┣━1 快速了解HBase.mhtml
┣━2 快速上手使用HBase.mhtml
┣━4 HBase高级用法.mhtml
┣━6 HBase核心复盘.png
┣━3 深入HBase架构原理.mhtml
┣━5 HBase调优策略和扩展内容.mhtml
┣━第11周-数据分析引擎之Impala
┣━3 Impala 高级内容.mhtml
┣━1 快速了解Impala.mhtml
┣━2 快速上手使用Impala.mhtml
┣━第12周-7天极速掌握Scala语言
┣━1 Scala极速入门.mhtml
┣━5 Scala高级特性.mhtml
┣━2 Scala基础语法.mhtml
┣━4 Scala函数式编程.mhtml
┣━3 Scala面向对象.mhtml
┣━6 Scala核心复盘.png
┣━第13周-Spark快速上手
┣━3 Spark实战:单词统计.mhtml
┣━7 Spark实战与核心复盘.png
┣━2 解读Spark工作与架构原理.mhtml
┣━5 RDD持久化.mhtml
┣━6 TopN主播统计.mhtml
┣━4 Transformation与Action开发.mhtml
┣━1 初识Spark.mhtml
┣━第14周-Spark性能优化的道与术
┣━1 Spark三种任务提交模式.mhtml
┣━2 Shuffle机制分析.mhtml
┣━7 Spark实战与核心复盘.mhtml
┣━3 Spark之checkpoint.mhtml
┣━4 Spark程序性能优化企业级最佳实践.mhtml
┣━5 Spark性能优化之算子优化.mhtml
┣━6 极速上手SparkSql.mhtml
┣━第15周-Spark 3.x版本扩展内容
┣━3 SparkSQL 集成 Hive.mhtml
┣━1 快速上手使用Spark3.mhtml
┣━2 Spark 3.x版本中新特性的原理及应用.mhtml
┣━第16周-综合项目:电商数据仓库之用户行为数仓
┣━3 电商数仓技术选型.mhtml
┣━5 用户行为数仓设计与实现.mhtml
┣━6 项目核心复盘.png
┣━1 电商数据仓库效果展示.mhtml
┣━4 数据生成与采集.mhtml
┣━2 数据仓库前置技术.mhtml
┣━第17周-综合项目:电商数据仓库之商品订单数仓
┣━2 需求设计与实现.mhtml
┣━3 订单拉链表实战.mhtml
┣━4 数据可视化和任务调度实现.mhtml
┣━1 商品订单数仓需求分析.mhtml
┣━5 项目核心复盘.png
┣━第18周-消息队列之Kafka从入门到小牛
┣━1 初识Kafka.mhtml
┣━7 Kafka技巧篇.mhtml
┣━2 Kafka集群安装部署.mhtml
┣━3 Kafka使用初体验.mhtml
┣━9 Kafka核心复盘.png
┣━4 Kafka核心扩展内容.mhtml
┣━5 Kafka核心之存储和容错机制.mhtml
┣━6 Kafka生产消费者实战.mhtml
┣━8 Kafka小试牛刀实战篇.mhtml
┣━第19周-极速上手内存数据库Redis
┣━5 Redis核心复盘.mhtml
┣━4 Redis高级特性.mhtml
┣━1 快速了解Redis.mhtml
┣━3 Redis封装工具类技巧.mhtml
┣━2 Redis核心实践.mhtml
┣━第1周-学好大数据先攻克Linux
┣━1 Linux虚拟机安装配置.mhtml
┣━2 Linux基础命令的使用【选修】.mhtml
┣━3 Linux极速上手.mhtml
┣━4 Linux试炼之配置与shell实战.mhtml
┣━6 面试题【作业】.mhtml
┣━5 Linux总结与走进大数据.mhtml
┣━第20周-Flink快速上手篇
┣━2 实战:流处理和批处理程序开发.mhtml
┣━1 初识Flink.mhtml
┣━3 Flink集群安装部署.mhtml
┣━7 Flink核心复盘.png
┣━4 Flink核心API之DataStream.mhtml
┣━5 Flink核心API之DataSet.mhtml
┣━6 Flink核心API之Table API和SQ.mhtml
┣━第21周-Flink高级进阶之路
┣━5 SparkStreaming快速上手.mhtml
┣━4 Flink之Kafka Connector专题.mhtml
┣━2 Flink中的Watermark深入剖析.mhtml
┣━1 Flink中的Window和Time详解.mhtml
┣━3 Flink中的并行度详解.mhtml
┣━6 Flink核心复盘.png
┣━第22周-Flink1.15新特性及状态的使用
┣━1 Flink新版本新特性介绍.mhtml
┣━2 快速上手使用Flink1.15.mhtml
┣━3 State(状态)的使用与管理.mhtml
┣━第23周-Flink 1.15之State(状态)的容错与一致性
┣━1 State(状态)的容错与一致性.mhtml
┣━2 Checkpoint与State剖析.mhtml
┣━3 Kafka连接器新API的使用.mhtml
┣━第24周-Flink1.15之Flink SQL快速上手
┣━4 Flink SQL中的列类型详解.mhtml
┣━8 SQL Client客户端工具.mhtml
┣━2 Flink SQL中的表类型详解.mhtml
┣━5 Flink SQL中的DML语句详解.mhtml
┣━1 Flink SQL快速理解.mhtml
┣━6 Flink SQL中的Catalog.mhtml
┣━7 Flink SQL如何兼容Hive.mhtml
┣━3 Flink SQL常见的数据类型.mhtml
┣━第25周-全文检索引擎Elasticsearch
┣━5 Elasticsearch的高级特性.mhtml
┣━1 快速了解Elasticsearch.mhtml
┣━2 快速上手使用Elasticsearch.mhtml
┣━3 Elasticsearch分词详解.mhtml
┣━6 Elasticsearch核心复盘.png
┣━4 Elasticsearch查询详解.mhtml
┣━第26周-ES+HBase实现仿百度搜索引擎
┣━1 企业中快速复杂查询痛点分析.mhtml
┣━6 项目核心复盘.png
┣━2 仿百度搜索引擎项目架构设计.mhtml
┣━3 ES高级特性扩展.mhtml
┣━5 项目中遇到的典型问题.mhtml
┣━4 开发仿百度搜索引擎项目.mhtml
┣━第27周-直播平台三度关系推荐V1.0
┣━5 数据采集+聚合+分发+落盘.mhtml
┣━6 数据计算核心指标分析.mhtml
┣━7 数据核心指标计算.mhtml
┣━4 数据采集模块分析.mhtml
┣━2 项目技术选型.mhtml
┣━3 Neo4j图数据库快速上手使用.mhtml
┣━1 项目介绍及演示.mhtml
┣━8 项目核心复盘.png
┣━第28周-直播平台三度关系推荐V2.0
┣━3 数据接口定义及开发.mhtml
┣━2 V2.0架构之数据核心指标计算.mhtml
┣━4 项目展示.mhtml
┣━5 项目扩展优化.mhtml
┣━1 V1.0架构方案分析及V2.0架构设计.mhtml
┣━6 项目核心复盘.png
┣━第29周-数据中台大屏
┣━2 数据中台架构.mhtml
┣━7 数据加工总线之SparkSQL计算引擎开发.mhtml
┣━4 数据中台企业级解决方案.mhtml
┣━9 后期展望.mhtml
┣━1 数据中台的前世今生.mhtml
┣━5 项目总结.png
┣━8 数据加工总线之FlinkSQL计算引擎开发.mhtml
┣━3 什么样的企业适合建设数据中台.mhtml
┣━6 数据中台之数据加工总线.mhtml
┣━第2周-大数据起源之初识Hadoop
┣━2 Hadoop的安装方式.mhtml
┣━1 初识Hadoop.mhtml
┣━第3周-Hadoop之HDFS的使用
┣━1 HDFS介绍.mhtml
┣━2 HDFS基础操作.mhtml
┣━3 Java操作HDFS.mhtml
┣━第4周-Hadoop之HDFS核心进程
┣━3 HDFS高级.mhtml
┣━4 Hadoop核心复盘.png
┣━1 初识NameNode.mhtml
┣━2 NameNode进阶.mhtml
┣━第5周-Hadoop之初识MR
┣━1 初识MapReduce.mhtml
┣━3 深入MapReduce.mhtml
┣━4 精讲Shuffle执行过程及源码分析输入输出.mhtml
┣━2 实战:WordCount.mhtml
┣━第6周-拿来就用的企业级解决方案
┣━3 YARN实战.mhtml
┣━4 Hadoop官方文档使用指北.mhtml
┣━5 Hadoop核心复盘.png
┣━1 剖析小文件问题与企业级解决方案.mhtml
┣━2 剖析数据倾斜问题与企业级解决方案.mhtml
┣━第7周-Flume从0到高手一站式养成记
┣━4 Flume出神入化篇.mhtml
┣━2 极速上手Flume使用.mhtml
┣━3 精讲Flume高级组件.mhtml
┣━1 极速入门Flume.mhtml
┣━5 Flume核心复盘.png
┣━第8周-数据仓库Hive从入门到小牛
┣━5 Hive高级函数实战.mhtml
┣━6 Hive技巧与核心复盘.mhtml
┣━1 快速了解Hive.mhtml
┣━3 Hive基础使用.mhtml
┣━2 数据库与数据仓库区别.mhtml
┣━4 Hive核心实战.mhtml
┣━第9周-Hive扩展内容
┣━1 常见数据压缩格式的使用.mhtml
┣━2 常见数据存储格式的使用.mhtml
┣━课程源码+软件包下载地址
┣━21个代码截图.png
┣━bigdata_course_materials-master(软件包下载地址在此).zip
┣━data_screen-master.zip
┣━db-sparkstreaming-master.zip
┣━db_data_process-master.zip
┣━db_data_warehouse-master.zip
┣━db_elasticsearch-master.zip
┣━db_flink-master.zip
┣━db_flink15-master.zip
┣━db_fullsearch-master.zip
┣━db_hadoop-master.zip
┣━db_hbase-master.zip
┣━db_hive-master.zip
┣━db_impala-master.zip
┣━db_kafka-master.zip
┣━db_redis-master.zip
┣━db_scala-master.zip
┣━db_spark-master.zip
┣━db_spark3-master.zip
┣━db_video_recommend-master.zip
┣━db_video_recommend_v2-master.zip
┣━hadoop-3.2.0-src-master.zip










评论1